Zeek-Kafka 之 硬盘舒服了!
写在前面
哎,今年上半年实在太忙了,工作中一些琐碎的事让我日常处于和技术“脱线”的状态。好不容易挤出一点时间来整理一下手头的东西,想着还有哪些可以拿出来给大家分享。
背景
由于流量镜像后的网络流量太大,若想利用Zeek将数据解析后进行分析,硬盘的空间以及I/O是我们必须考虑的。虽然我们可以写个脚本做定时任务清除,但这并不是最优解决方案。至少在我的场景中这些数据都是需要发送到Kafka上的,如果能做到在数据源阶段就不用落地在本地磁盘岂不美哉?所以,我需要对数据采集后的写入方式进一步优化。
优化前
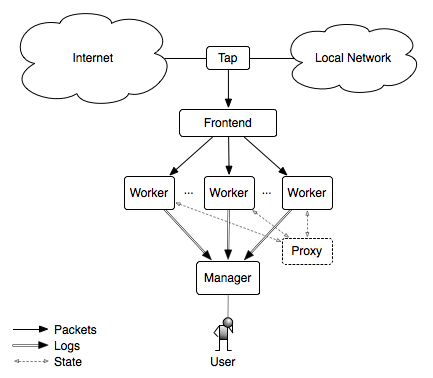
Zeek将日志留存在本地硬盘,由本地安装的filebeat发送给Kafka,最终落地到SIEM上。

优化后
Zeek日志将不会留存在本地硬盘上,由Zeek Kafka插件将日志发送到Kafka集群,省去了数据落盘的步骤。

安排
之前就有了解过Zeek可以通过插件的形式将日志发送到Kafka上,由于当时没有需求也就没有继续探究,想着这次需求来了就开启了“折腾”模式。本次我使用的是Zeek-Kafka这个插件,很多网上的文章介绍的插件是 metron-bro-plugin-kafka。大家可以认为这个是Zeek-Kafka的前身,后者(metron-bro-plugin-kafka)已经并没有在更新了。使用的话还是推荐Zeek-Kafka。
安装
安装流程比较简单,参考文档Zeek-Kafka即可。至此文章结束。下期再会!
知识点
OK,在开始之前我们来聊一下使用了这个插件之后我认为需要调整的地方以及一些Zeek知识点的补充。
重新认识Zeek日志框架
为什么这么说?上面有说到,我做此事的目的是为了节省硬盘空间、降低I/O的压力。实际在我使用此插件时,它会把日志发送到Kafka集群并同时保留原始的日志数据在本地硬盘(擦,忙活半天,搞了个寂寞!)。不过,至少确认日志发送到Kafka是OK的,现在我们只需要有选择性的drop掉写入硬盘的操作即可。为了满足这个需求,就需要我们先了解一下Zeek - Logging Framework(日志框架)。由于我之前写过一些Zeek的检测场景,对于这个框架并不陌生,只不过理解上不够深入,经过这一次,算是比之前有了更加深入的理解。
Zeek 的日志接口是围绕三个对象构建的:

Streams(流)
一个日志流对应于一个单一的日志。它定义了一个日志所包含的字段的集合,以及它们的名称和类型。例如,conn流用于记录连接摘要,http流用于记录HTTP活动。
Filters(过滤器)
每个流都有一组过滤器,决定哪些信息被写出来,以及如何写出来。默认情况下,每个流都有一个默认的过滤器,直接把所有的东西都记录到磁盘上。然而,可以添加额外的过滤器,只记录日志记录的一个子集,写到不同的输出,或者设置一个自定义的旋转间隔。如果从一个流中删除所有的过滤器,那么该流的输出就会被禁用。
Writers(写入器)
每个过滤器都有一个写入器。写入器定义了被记录信息的实际输出格式。默认的是ASCII写入器,它产生以制表符分隔的ASCII文件。其他写入器是可用的,比如二进制输出或直接记录到数据库。
简单总结:Streams与Filters关系是一对多,Filters与Writers关系是一对一。
我们可以用以下几种方式来定制Zeek的日志:
创建一个新的日志流
用新的字段来扩展现有的日志
对现有的日志流应用过滤器
通过设置日志写入器选项来定制输出格式
根据我们的需求,这里选择方案3(对现有的日志流应用过滤器)。你会用到的方法如下:
- 删除指定流的过滤器:Log::remove_filter
- 创建一个新的过滤器:Log::Filter
- 绑定过滤器与流关系:Log::add_filter
- 获取指定流的过滤器:Log::get_filter
以下任意一种方式都可以满足我们的需求,既原始日志不会落地在硬盘且直接写入Kafka集群。
示例代码1:删除默认过滤器
1 | event zeek_init() &priority=-10 |
示例代码2 - 修改默认过滤器
1 | event zeek_init() &priority=-10 |
真实场景
场景1:适配HTTP的文件还原(file-extraction-plus)场景
kafka/kafka-config.zeek
定义Kafka集群的配置
1
2
3
4
5redef Kafka::kafka_conf = table(
["metadata.broker.list"] = "node-1:9092,node-2:9092,node-3:9092"
);
redef Kafka::json_timestamps = JSON::TS_ISO8601;file-extraction-plus/http-extension-logs.zeek
优化file-extraction-plus(文件还原)脚本,这里需要为文件还原的HTTP日志新增过滤器(http_extraction),确保能够被接下来引用。因此,需要用到Log::PolicyHook方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32module Enrichment;
redef record HTTP::Info += {
extract: bool &default=F &log;
domain: string &optional &log;
};
hook HTTP::log_policy(rec: HTTP::Info, id: Log::ID, filter: Log::Filter)
{
if ( filter$name != "http_extraction" )
return;
if ( rec$extract == F )
break;
}
event zeek_init()
{
local filter: Log::Filter = [$name="http_extraction", $path="http-extraction"];
Log::add_filter(HTTP::LOG, filter);
}
export {
global http: function(f: fa_file): fa_file;
}
function http(f: fa_file): fa_file
{
f$http$extract = T;
f$http$domain = f$http$host;
return f;
}kafka/http_extraction-to-kafka.zeek
利用Log::get_filter方法获取过滤器(http_extraction),通过将写入器修改为WRITER_KAFKAWRITER。最终实现将命中文件还原的HTTP事件通过指定topic(zeek-http_extraction)发送到Kafka。
1
2
3
4
5
6
7
8event zeek_init() &priority=-10
{
local f = Log::get_filter(HTTP::LOG, "http_extraction");
f$writer = Log::WRITER_KAFKAWRITER;
f$config = table(["topic_name"] = "zeek-http_extraction");
Log::add_filter(HTTP::LOG, f);
}场景2:算是场景1进行扩展,在保留HTTP文件还原的日志前提下,将全量的HTTP数据发送到指定的topic(zeek-http)。
- kafka/kafka-config.zeek
1
2
3redef Kafka::kafka_conf = table(
["metadata.broker.list"] = "node-1:9092,node-2:9092,node-3:9092"
);- kafka/http-to-kafka.zeek
1
2
3
4
5
6
7
8event zeek_init() &priority=-10
{
local f = Log::get_filter(HTTP::LOG, "default");
f$writer = Log::WRITER_KAFKAWRITER;
f$config = table(["topic_name"] = "zeek-http");
Log::add_filter(HTTP::LOG, f);
}
对比
这里用PCAP包回放的形式给大家验证一下前后的对比,为了便于验证,我这里只针对HTTP数据送入到了Kafka。
修改前
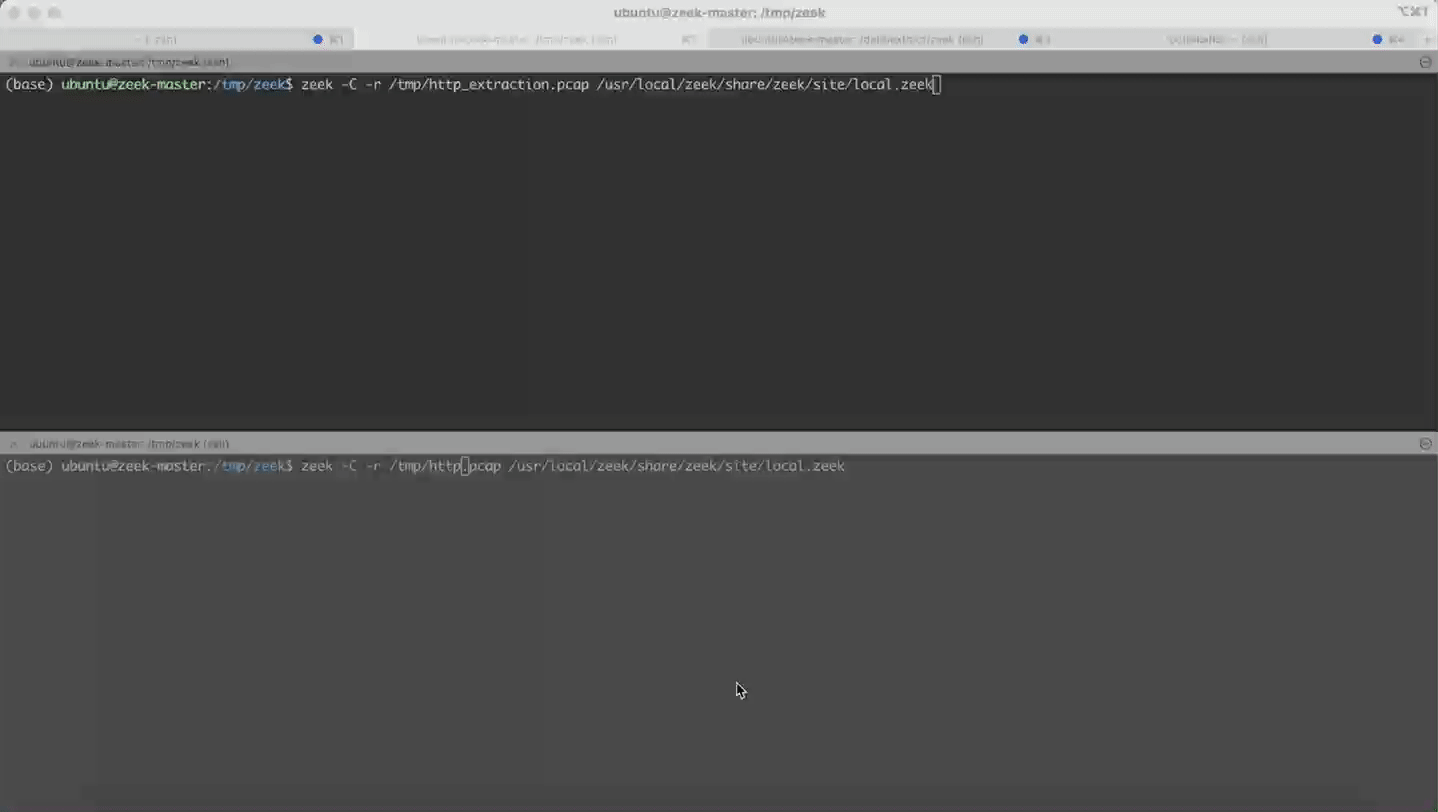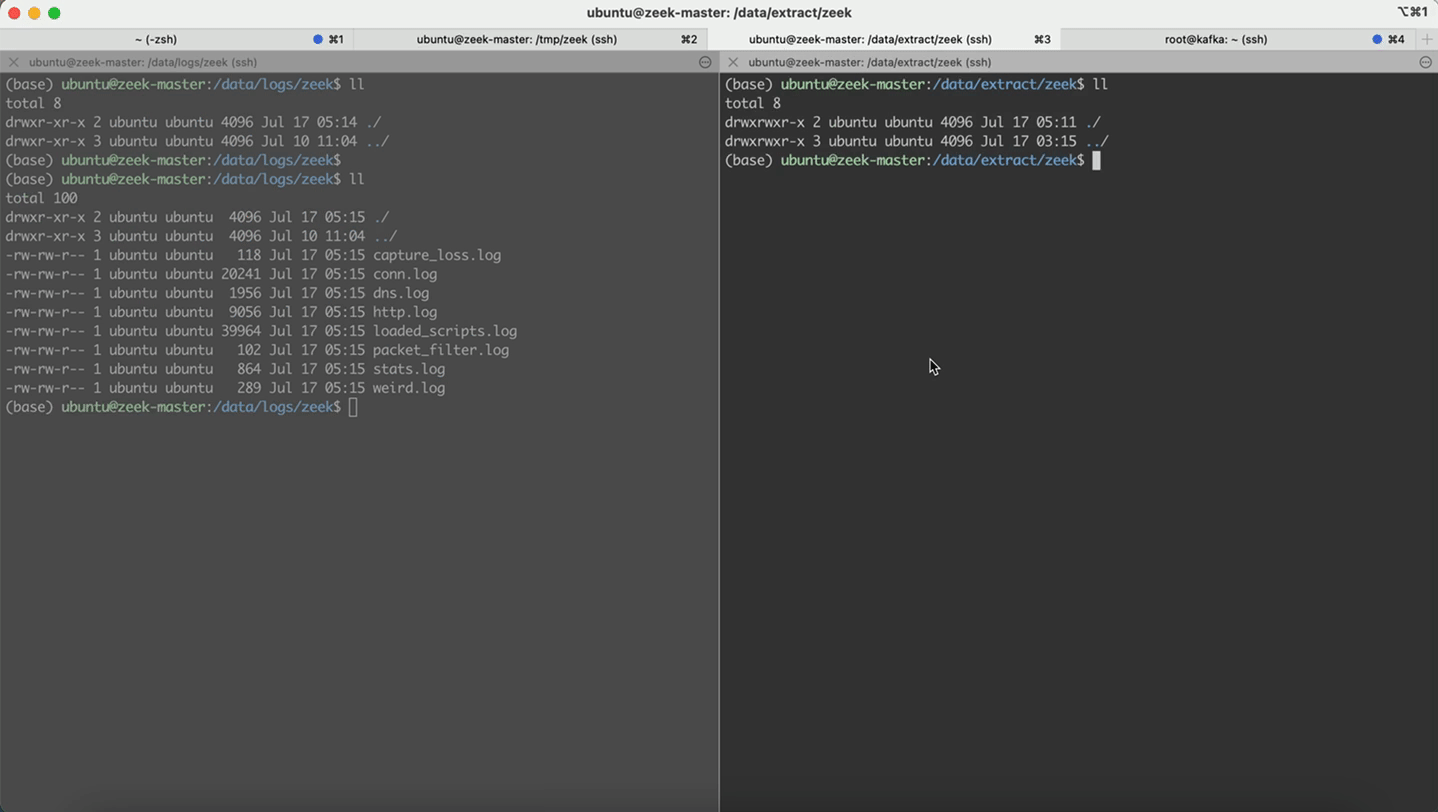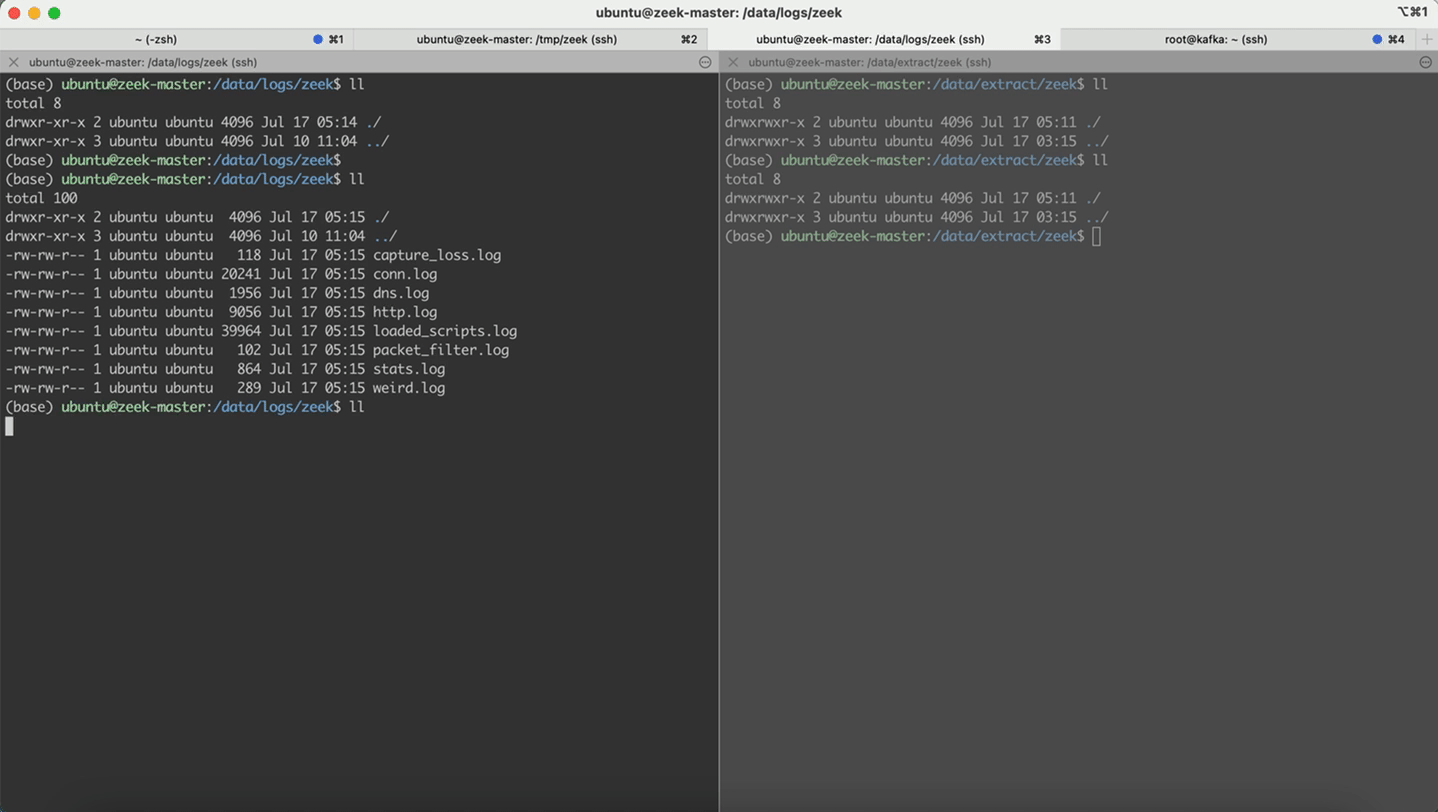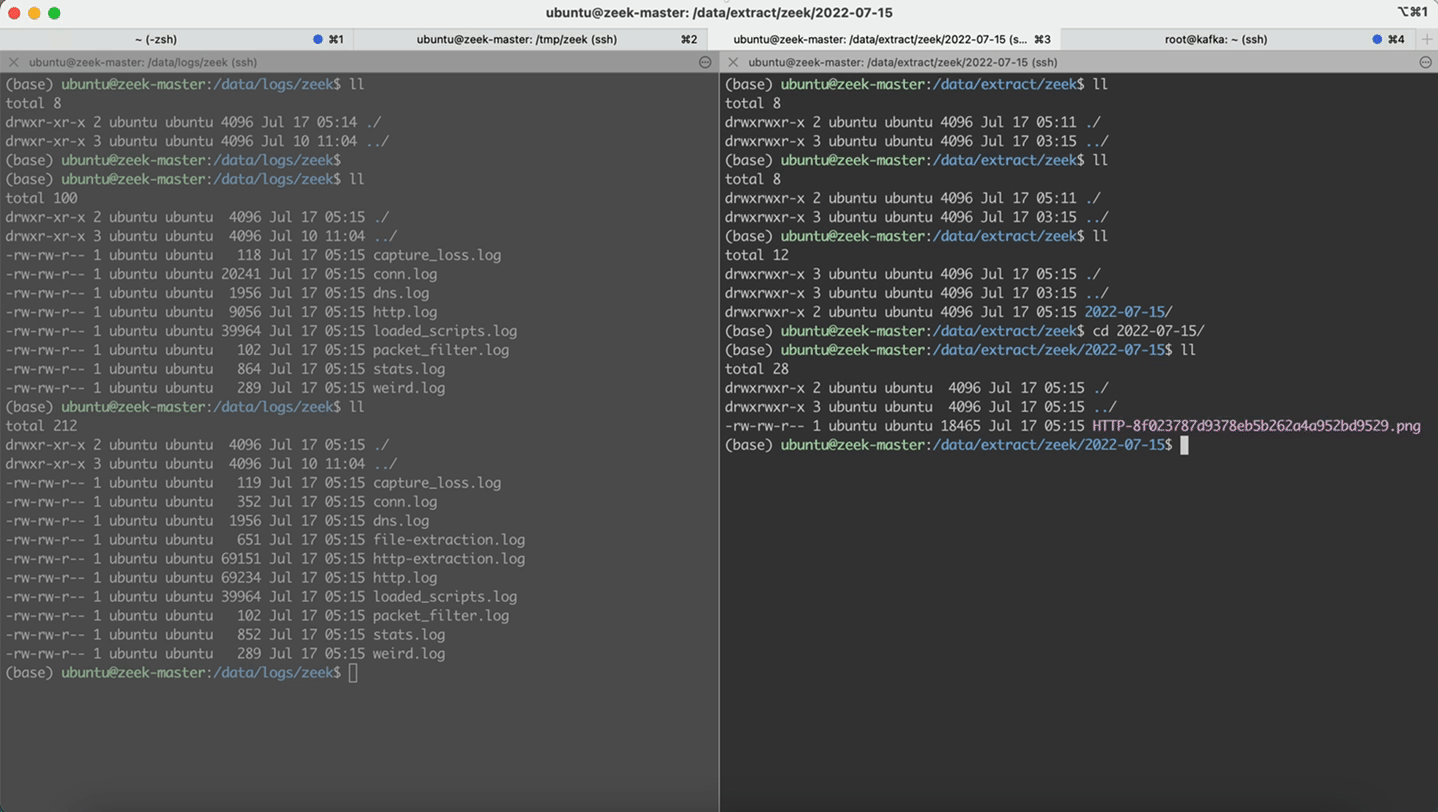
- 回放http.pcap,本地会留存 http.log
- 回放http_extraction.pcap,本地会留存http-extraction.log
修改后
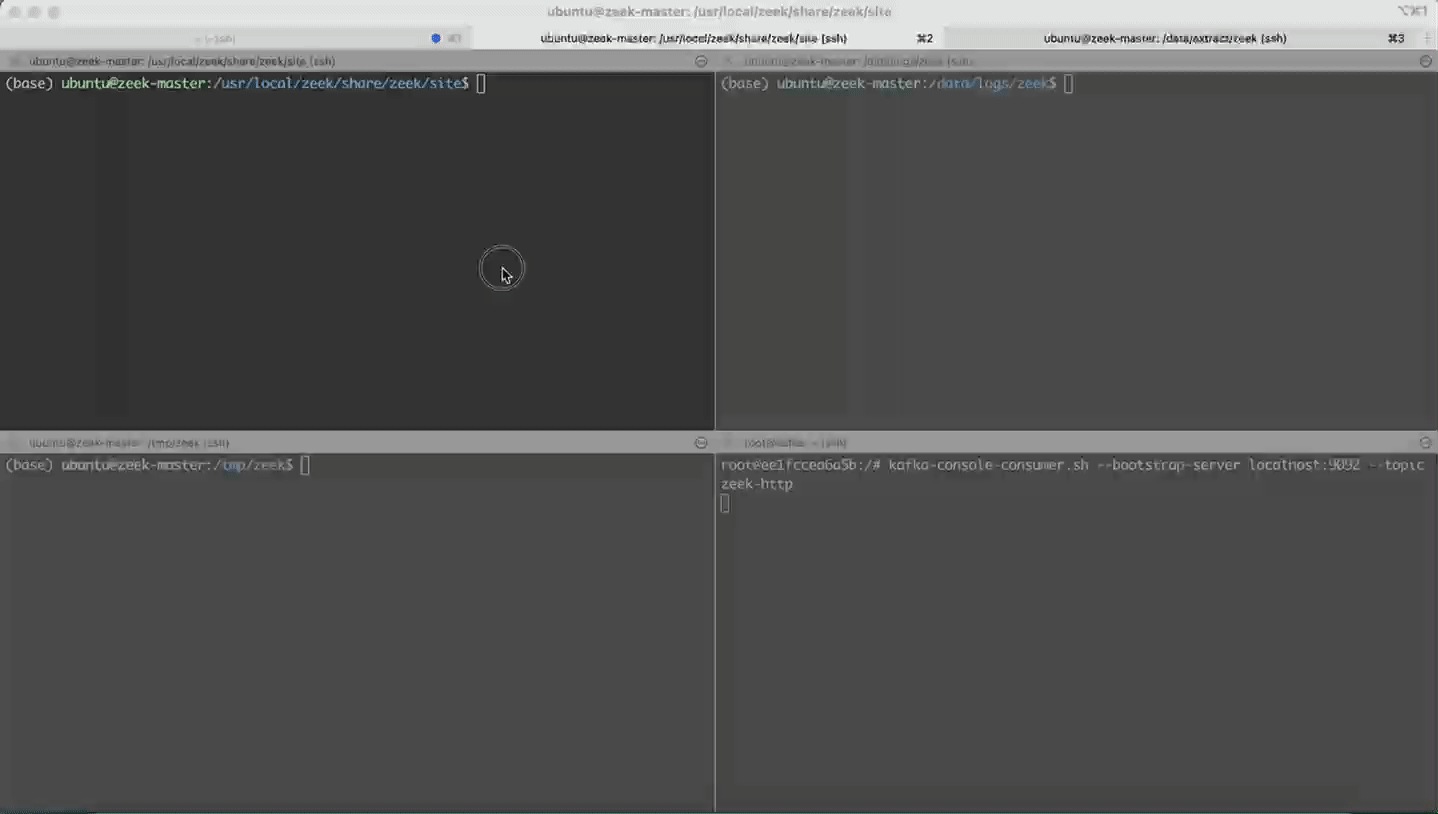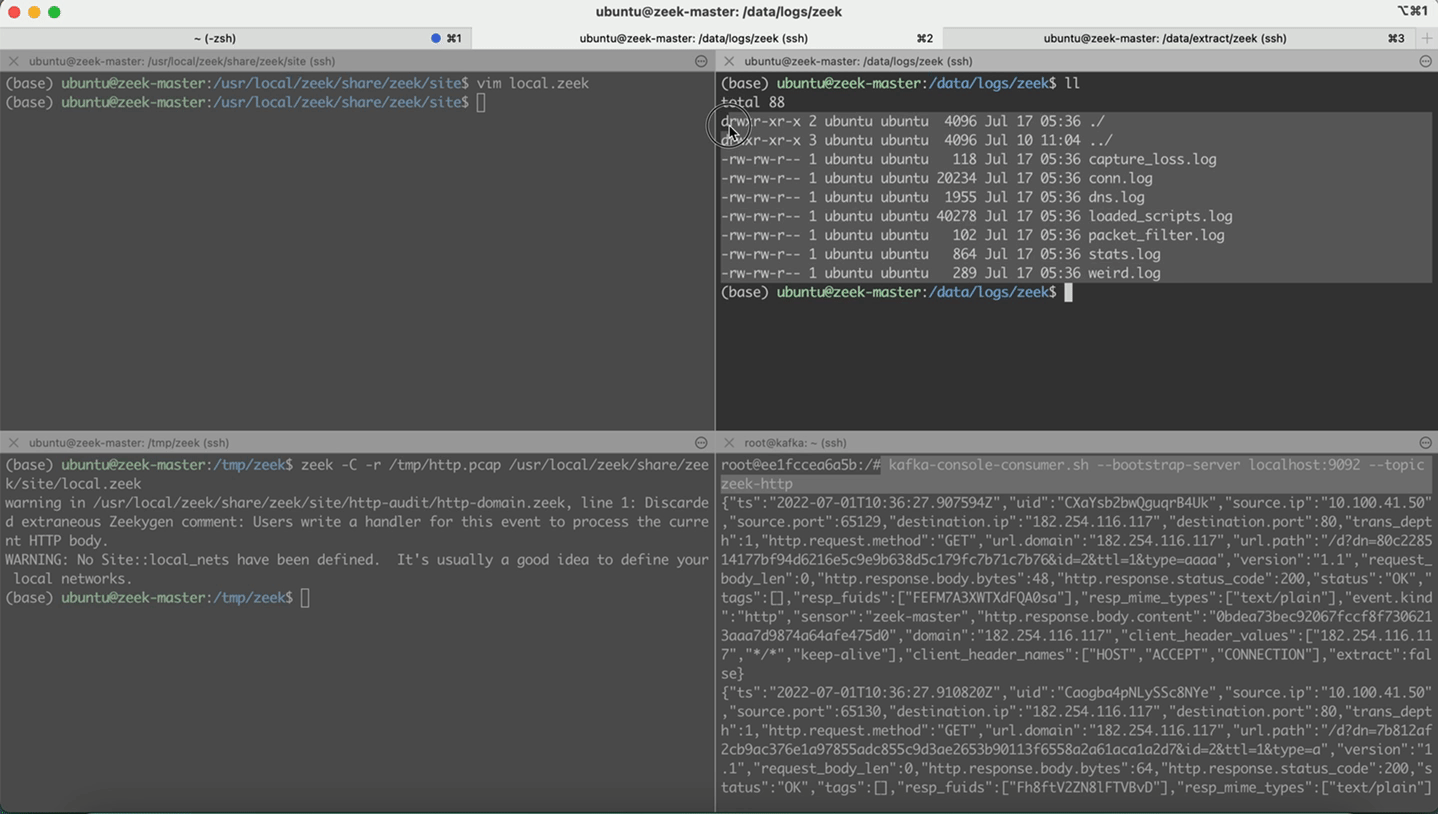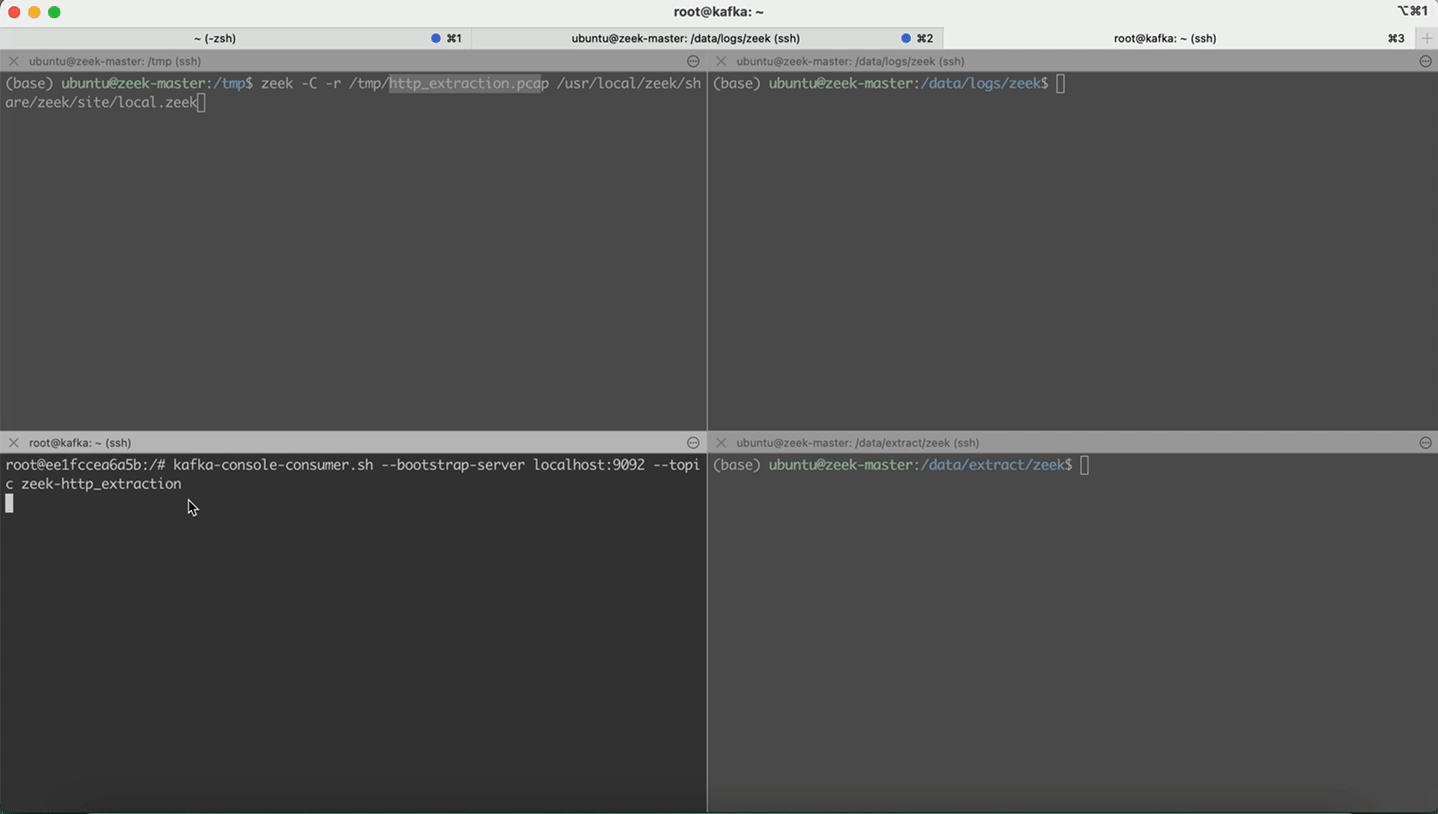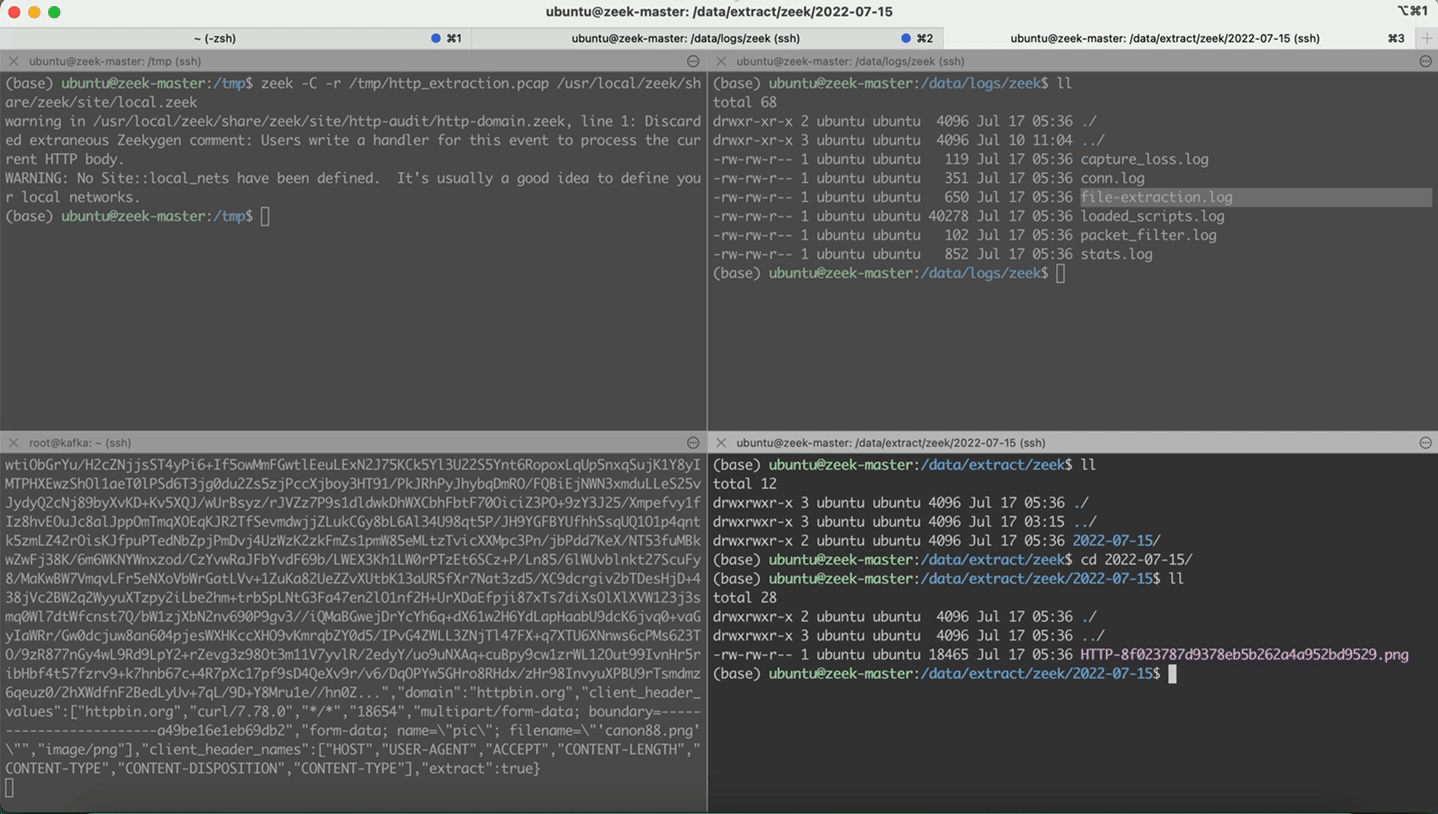
- 回放http.pcap,本地无http.log。topic: zeek-http,存在日志
- 回放http_extraction.pcap,本地无http-extraction.log。topic: zeek-http_extraction,存在日志
最后
下一篇 《Zeek-Kafka 之 机器受不了!》将会向大家介绍,若想在实际环境中完全发挥Zeek-Kafka插件的能力,我们的架构也需要进行一些调整,一起探索Zeek集群的模式吧。