如何“优雅”的设计Playbook
写在最前面
开源是“理念”,分享是“精神”。拒绝一切“对号入座”!

背景
之前有写过一篇Blog(致我心中的“散装”SOAR,当Thehive遇到n8n),主要是介绍如何通过Thehive + n8n形成最“简(基)陋(础)”的SOAR。本篇Blog灵感主要是来源自己平时的思考与总结。那么,让我带领你深入浅出地探索编排的“艺术”,并展示如何“优雅”的设计一个剧本。说实话,当我说出这些“骚”话的时候,我竟一点都不觉得害臊。。。

优雅的设计一个剧本
设置一个Layer1 Workflow,作为告警的入口。同时指定一个Layer2 Workflow,作为结果的输出。这个Workflow中我的Kafka Topic是根据设备类型进行区分的,目的是便于后期进行扩展与维护。
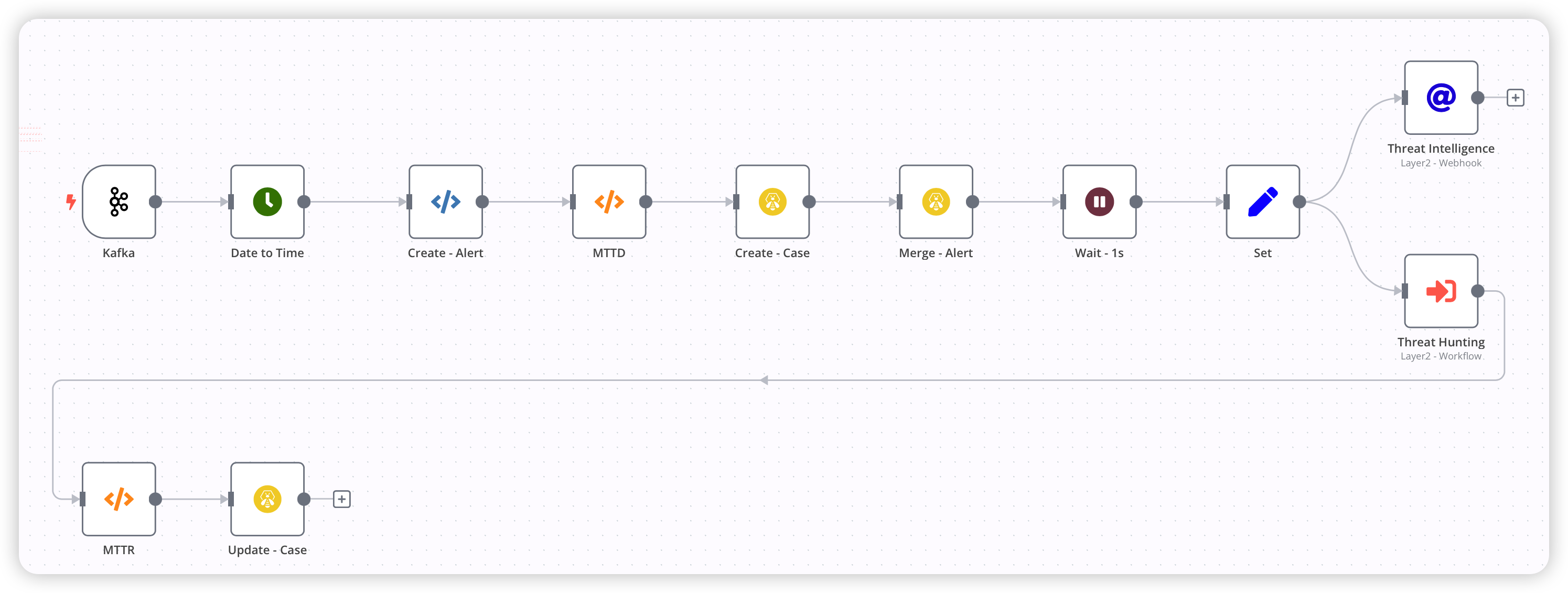
Q:为什么选择按照设备类型进行接入?
A:主要是出于性能方面的考虑。试想如果你日常的告警数据量比较大,很可能会频繁“拉起”这个Workflow,其实并不是每个告警都“值得”你去跑Workflow。当然你的告警数据量不大的话,可以不用区分。在这里,我选择了按照设备类型来区分,这也方便我后续按照设备类型的不同做一些微调。
Q: 为什么不直接扩展Layer1 Workflow?
A:主要还是考虑到可扩展性。我个人理解的“编排”就和你写代码的思维方式差不多,你得让你的Workflow足够的健壮以及剧本一定的伸缩性。应尽量避免因为某个需求,而导致你需要对现有Workflow进行“手术”。相信我,你会很痛苦的!正因如此,我没有选择直接在Layer1进行扩展。避免出现“屎山”代码,剧本也一样如此。
Q:为什么图中Threat Intelligence用的是Webhook,而Threat Hunting是Workflow?
A:至于原因嘛,主要是n8n不支持在同一个Workflow中并行运行Node,且也并不是所有Node都支持异步。好在HTTP Node是支持异步的,所以,当有异步需求或者并行处理需求的时候,我们可以使用Webhook这种方式调用Workflow。算是“曲线救国”吧,不知道未来版本会不会支持。当时在社区也专门开贴讨论过,更多请戳:Does n8n Workflow support parallel execution?
设置一个Layer2 Workflow,它用于承载Layer1的“需求”。
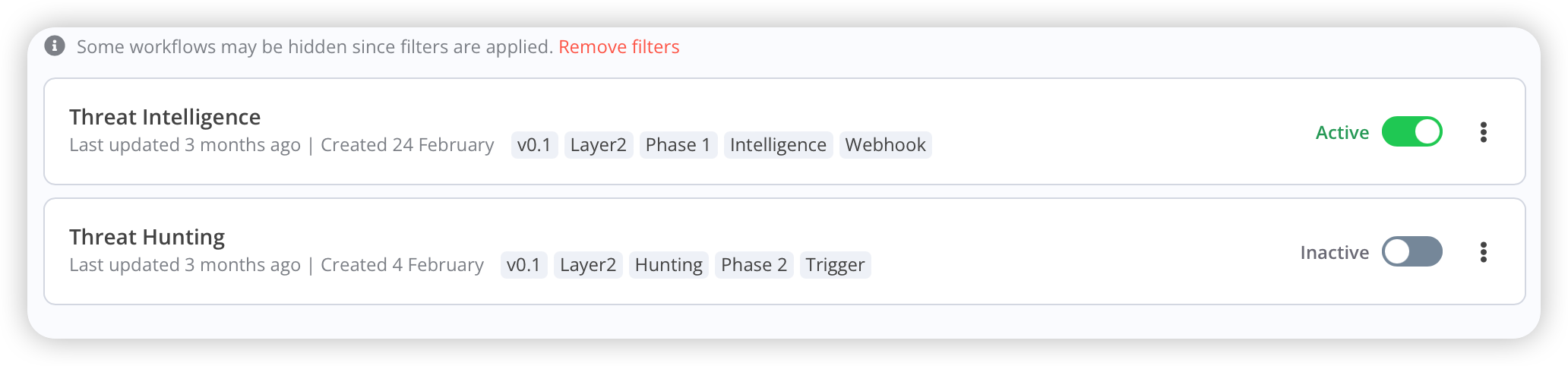
Q:为什么你会选择创建Threat Intelligence、Threat Hunting做为Layer2的Workflow?
A:其实这里还是考虑到可扩展性的关系,Layer2 Workflow它即要承接Layer1 Workflow的“需求”,同时也要为Layer3 Workflow提供“支撑”。所以,Layer2本身就必须有很强的扩展性,我建议你可以把它想象成编程中的“Class”。
Q:编写Workflow有什么参考规范吗?
A:编写Workflow并没有固定的规范,其设计完全依赖于作者的逻辑。但是,当我们将其用于事件响应(Incident Response, IR)时,我认为可以参考NIST发布的《计算机安全事件处理指南 (SP 800-61)》作为框架。这将帮助我们将当前的Workflow映射到IR的各个阶段,使我们在设计Workflow时更明确其“主要职责”。如果可以每个阶段都可以设计Workflow,以便更有效地应对特定的安全事件,当然这太过于理想化。以下是各阶段的详细介绍:
- 准备阶段(Preparation):这个阶段包括配置和维护所有必要的安全工具和系统,以便能够有效地检测和应对安全事件。这包括设置和配置SOAR工具,以便它们能够与其他安全系统(如防火墙,入侵检测系统等)集成,并且能够接收并处理威胁情报。
- 检测与分析阶段(Detection & Analysis):这是威胁情报和威胁狩猎最活跃的阶段。威胁情报可以帮助你识别和了解新的或已知的威胁,而威胁狩猎则是一个主动寻找未被发现的威胁的过程。
- 遏制阶段(Containment):一旦检测到威胁,即应用预设的自动化流程去遏制威胁,例如隔离受影响的系统或阻止恶意的网络流量。
- 消除阶段(Eradication):在这个阶段,会移除系统中的威胁组件,修复漏洞并应用补丁。
- 恢复阶段(Recovery):这个阶段的目标是恢复被攻击的系统和服务,确保一切回到正常状态。
- 经验总结阶段(Lessons Learned):在应急响应结束后,应对整个事件进行回顾,总结经验教训,提升未来的应急响应效率。
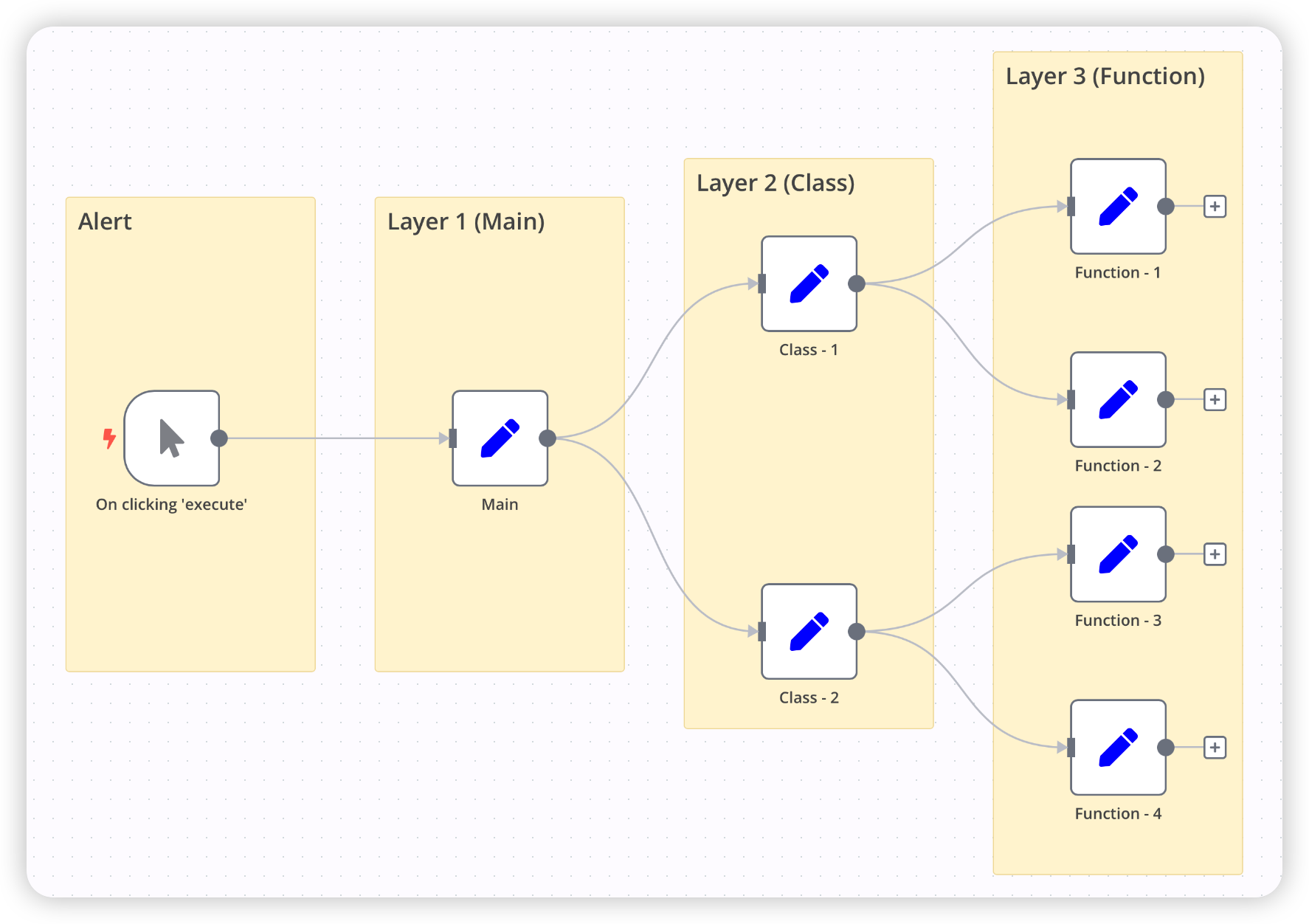
我通常将剧本会分为3层(Layer1 ~ Layer3),通常Layer3这一层的都是底层“打工仔”,就跟此刻的你一样。
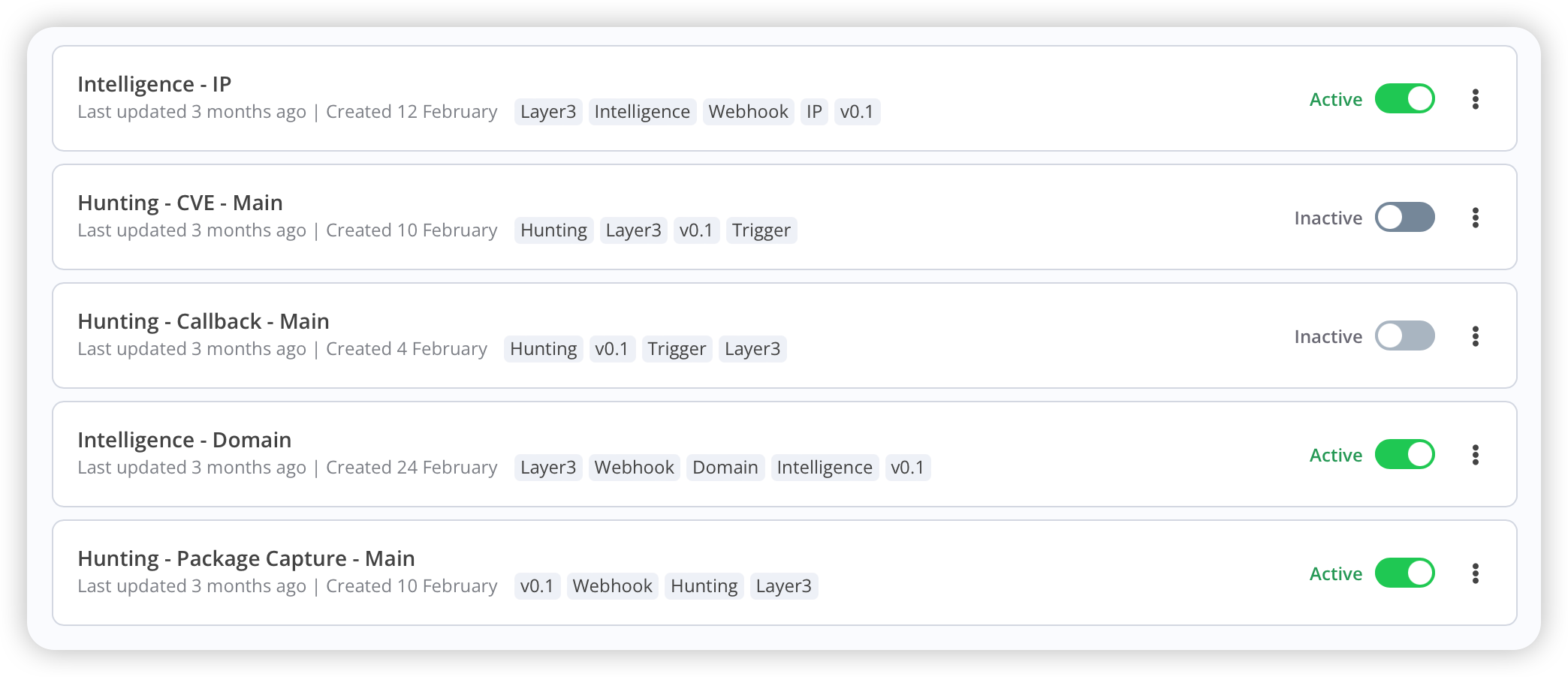
Q:设计Layer3的Workflow时,要足够灵活且尽可能的“独立”。
A:灵活是指,Layer3即支持被Layer2调用,也要支持通过从HTTP API的方式进行调用,便于后期与自动化进行整合。例如,通过TheHive的Cortex调用Layer3的Workflow,它不香?独立是指:在设计Layer3的时候,需要考虑与Layer2的“亲(耦)密(合)度”,尽可能的模块化,便于其他场景的Workflow单独引用与封装。
Q:Layer3是最后一层吗?之后会有Layer4、Layer5吗?
A:这完全取决于Layer3的“规模”,如果你的Layer3比较复杂,为了更加精细化管理Layer3。可以考虑新增Layer4,此时Layer3将从“底层打工人”升级成了“头号打工仔”,升职加薪,指日可待!
总结
我认为一个“优雅”的IR Playbook框架,至少需要3层。为什么?其实,你尝试以编程的逻辑去理解它就很容易了。Layer1就是功能“入口”,Layer2则是Class,而Layer3就应该是Function。
一个优秀的Playbook,像极你的老板对你的要求:“既要、又要、还要”
- 既要:具有高效的自动化流程,优化安全团队的响应时间
- 又要:有灵活的设计,以便适应各种安全事件的特性
- 还要:易于维护和更新,以便随着威胁场景的变化和组织需求的变化进行调整